 inspect
inspect
Parsing large XML files in node
Parsing large XML files in node
I recently had to parse relatively large XML files (multi GB) to export product data to a 3rd party API using node. Although this may sound like a trivial task at first, I found a few interesting challenges along the way.
Library choice
xml-stream
I started with this library, although very old, it seemed to offer a good balance of streamable event based parsing without too much difficulty extracting the data. The library eventually wraps the c library libexpat so I expected good performance.
However I had issues with native code compatibility running it in AWS lambda.
/var/task/node_modules/node-expat/build/Release/node_expat.node: invalid ELF header
I came to the conclusion that some dependency of libexpat was not available in the lambda runtime or that some pre-built binary wasn’t compatible.
SAX
In the hope to resolve my native code compatibility issues, I turned to sax, a very popular pure javascript implementation written by issacs (creator of npm). This did indeed resolve my issues in AWS lambda, however with my first implementation, I found it a lot more memory intensive than xml-stream. I started to have out of memory issues especially when parsing the larger files (more on that later). It was also somewhat slower than xml-stream.
Rust + neon
This was a little out there and more out of curiosity for performance benchmarks. I had a little experience building a node js wrapper for a rust crate using neon. I wondered if I could wrap something like quick xml and get the best performance. It turned out my rust skills were not quite up to the task.
sax-wasm
After my adventures in rust, I came across sax-wasm. I wondered if I could benefit from near native performance without the compatibility issues by using something wasm based. My initial results were promising, however despite a very responsive and talented maintainer, it became clear that the library was a little young to be used in production code (lack of documentation, some bugs with cdata, updated versions that broke). I did eventually get my code to work, but decided that the more productive way forward was to stick with sax and optimise my shoddy XML parsing code rather than search for a silver bullet library.
Out of memory issues
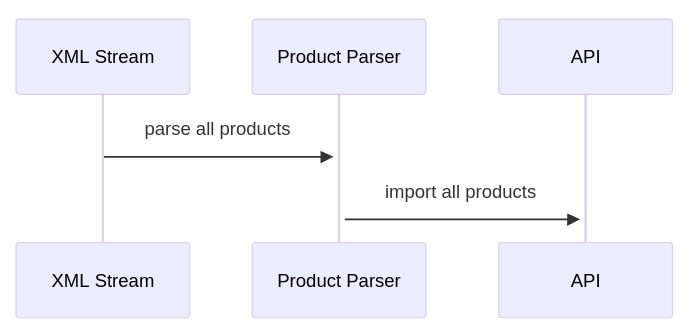
Although I never stored the entire file in memory, my initial strategy was to keep an array of all the product objects I’d parsed in memory until the full file had been read. Once the file had been parsed, I then batched requests to the api until all the products had been imported.
To fix the memory issues I changed strategy and came up with a threshold. I would keep the parsed products in memory until that threshold was reached, then send them off to the api, then fill up the next batch until all the products were imported.
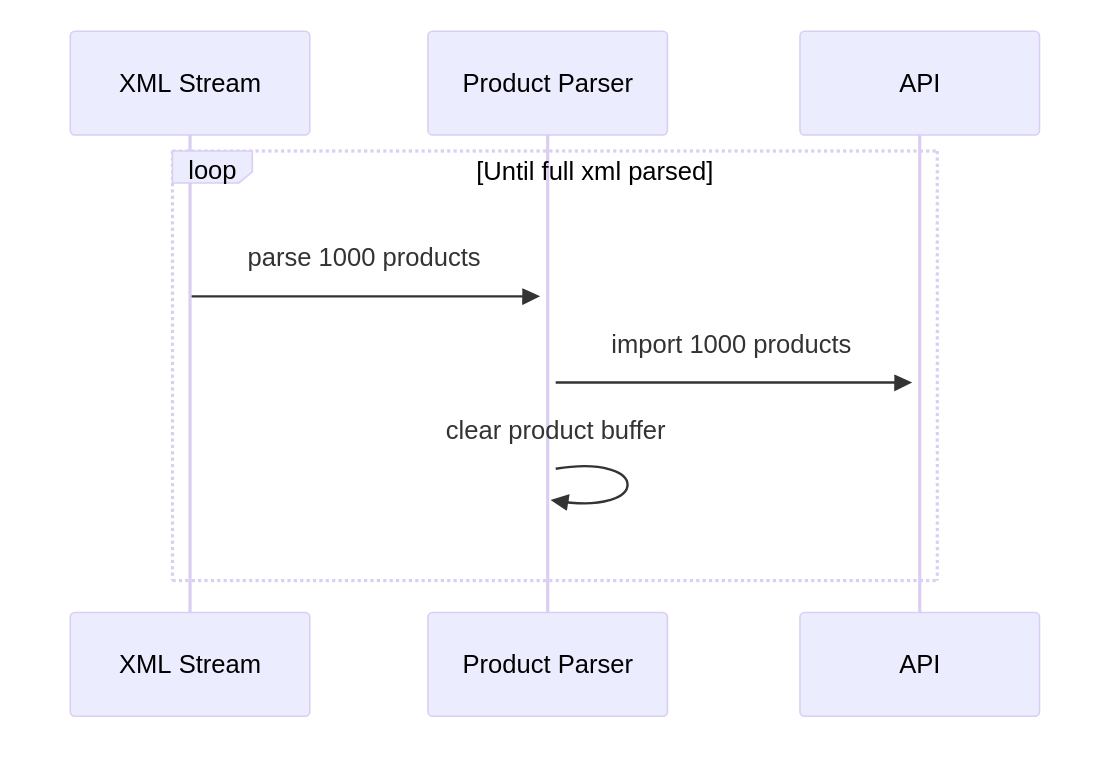
The sax library is an event emitter, you pass it an XML readable stream and it fires events when it sees various XML related entities. I decided to implement my own event emitter that would send events as the products were parsed.
Here’s a highly simplified version. with all the error handling and the vast majority of the parsing logic removed.
to parse this XML:
<products>
<product>
<name>Fancy Trainers</name>
</product>
</products>
Use the following class
import sax from "sax";
import {EventEmitter} from "node:events";
class ProductParser extends EventEmitter {
parse(readableStream) {
const xml = sax.createStream(strict, options);
let product = null;
let currentTag = null;
xml
.on("opentag", (tag) => {
if (tag.name === "product") {
product = {};
}
currentTag = tag.name;
})
.on("text", (text) => {
if (currentTag === "name" && product) {
product.name = text;
}
})
.on("closetag", (tag) => {
if (tag.name === "product") {
// product is done, notify new product
this.emit("product", product);
product = null;
}
})
.on("end", () => {
// file has finished parsing
this.emit("end");
});
readable.pipe(xml);
}
}
Then orchestrate like this
async function importCatalogue(xmlStream) {
return new Promise((resolve) => {
const THRESHOLD = 1000;
const productParser = new ProductParser();
let products = [];
productParser
.on("product", async (product) => {
products.push(product);
if (products.length >= THRESHOLD) {
const batch = [...products];
// this is the important step. Reassigning 'products' prevents storing all products in memory.
products = [];
await api.import(batch);
}
})
.on("end", async () => {
if (products.length) {
await api.import(products);
}
resolve();
})
.parse(xmlStream);
});
}
This strategy worked well, I observed the memory usage of my application increase on start up then flatten out while it was going through all of the products.
However, it led me to a subtle unpredictable bug…
Async event emitter handlers
Notice how the promise is resolved in the 'end' event handler? Well the
problem is that if one of the api.import() calls is slow, we could resolve the
promise before the products have imported.
When running node locally, this isn’t a such a big problem because node waits for any asynchronous activity before exiting. However AWS lambda simply waits for your handler to complete (in this case to resolve).
This led to some batches being prematurely cut off without an obvious error or explanation.
The fix I came up with, was to store the promises and await them in the end handler.
const pendingHandlers = [];
productParser
.on('product', (product) => {
pendingHandlers.push((async () {
products.push(product);
if (products.length >= THRESHOLD) {
const batch = [...products];
products = [];
await api.import(batch);
}
})())
})
.on('end', async () => {
// Ensure all pending requests have completed
await Promise.all(pendingHandlers);
if (products.length) {
await api.import(products);
}
resolve();
})
.parse(xmlStream)
This worked pretty well, however I found another issue.
Requests being delayed and timing out
Although the requests were being sent out as parsing was going on, I found that these were taking a very long time to complete.
On top of this, although I saw some improvement on memory usage, it was still continuously increasing until the full file was parsed.
My explanation to this is that the XML parsing is flooding the node js event loop with events so many events, that the callbacks used during the api request end up very far behind in the queue.
One solution to this may have been to use worker threads to send the api requests however, I didn’t like the idea of going down the multi threaded route in javascript.
Thankfully I came across this github issue in sax.
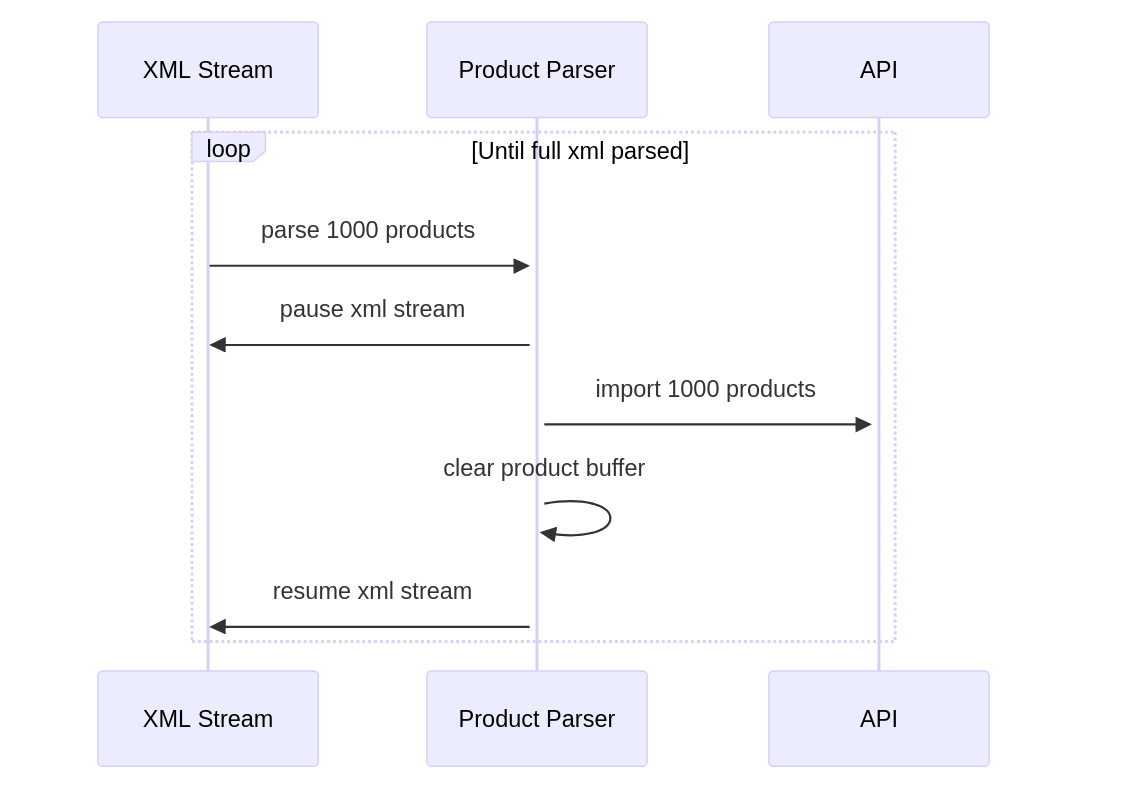
It turns out that readable streams have
pause() and
resume() functions which
allow you to stop piping data while you perform some operation, then continue
once you’re finished. So I changed my code to.
productParser
.on('product', (product) => {
pendingHandlers.push((async () {
products.push(product);
if (products.length >= THRESHOLD) {
const batch = [...products];
products = [];
// stop pipeing data while the api request is sent
xmlStream.pause();
await api.import(batch);
// continue pipeing data
xmlStream.resume();
}
})())
})
Success!
I was now able to import large xml files without running out of memory, what took 7GB of memory initially was reduced to 2GB without increasing the time taken.